

Amplificación de amplitudes
La amplificación de amplitudes puede interpretarse como una primitiva cuántica, es decir como un algoritmo que se abstrae de la implementación y que es reutilizable en otros algoritmos. Por ejemplo, el algoritmo de Grover lo utiliza para un problema de búsqueda en particular.
Objetivo
Sección titulada «Objetivo»La amplificación de amplitudes busca generalizar el algoritmo de Grover, preservando la mejora cuadrática y permitiendo la búsqueda sobre un conjunto de elementos no estructurado sin las restricciones impuestas por el mismo. De esta manera, no necesariamente los elementos deben disponerse en una superposición uniforme, y puede haber ninguna, una o varias soluciones. Además, la amplificación de amplitudes pretende funcionar correctamente incluso cuando se desconoce la cantidad de soluciones de antemano.
Solución
Sección titulada «Solución»Si el espacio de búsqueda posee elementos, es posible poner el foco sobre su índice, el cual puede enumerarse desde hasta . Así, se asume la igualdad de manera que el índice pueda ser almacenado en bits. A su vez, el problema puede tener soluciones, con . Una instancia del problema de búsqueda puede ser representada por una función , que toma un entero como entrada dentro del rango que va desde hasta . Por definición, si es la solución del problema, y en caso contrario.
El algoritmo de amplificación de amplitudes se divide en tres partes: la preparación, la selección y el reflejo.
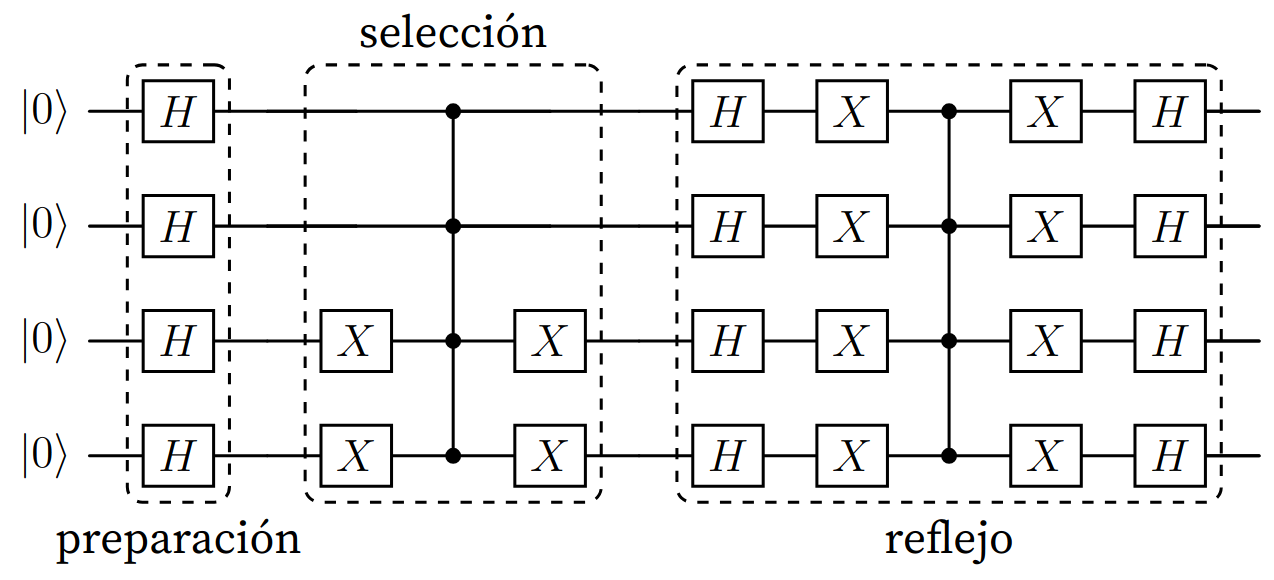
Figura (1): Estructura de la primitiva de amplificación de amplitudes (AA), con superposición uniforme y que selecciona al estado .
Preparación
Sección titulada «Preparación»La etapa de preparación denota una precondición del algoritmo: que el estado cuántico se encuentre en superposición. La forma en la que será implementada dependerá del problema en cuestión. Generalmente, se habla de un algoritmo cuántico que no realiza mediciones durante su ejecución.
El resultado de aplicar dicho algoritmo sobre el estado inicial es el siguiente:
Selección
Sección titulada «Selección»En la etapa de selección, se provee un circuito que distingue los estados cuánticos a buscar. Esto se hace mediante la modificación de la fase de los estados “buenos”, es decir, que conforman una solución. Para ello, se acude a la función antes definida.
En el ejemplo provisto en la figura 1, se implementa con una puerta CZ, marcando el estado , por lo que solo se invertirá la fase para dicho estado. Normalmente se utilizan subrutinas más complejas para invertir las fases. Por ejemplo, en ciertos algoritmos esta etapa se implementa utilizando un oráculo de fase, como ocurre en el algoritmo de Grover.
Reflejo
Sección titulada «Reflejo»Finaliza con la etapa de reflejo, que en ciertas bibliografías se lo llama operador de difusión (Grover) o inversión sobre la media (Nielsen y Chuang). Se convierten las diferencias de fases en contrastes de magnitud y se deselecciona los estados marcados en el paso previo.
Iteración
Sección titulada «Iteración»El proceso de amplificación se realiza mediante la aplicación repetida de las etapas de selección y reflejo sobre el estado resultante de la etapa de preparación. Cada iteración comprende la aplicación del siguiente operador unitario:
Donde cambia condicionalmente el signo de las amplitudes de los estados buenos, cambia el signo de la amplitud si y sólo si el estado es , y representa un algoritmo cuántico que no realiza mediciones durante su ejecución y, por lo tanto, posee inversa.
Análisis
Sección titulada «Análisis»Para evaluar el comportamiento del algoritmo se definen dos conjuntos de cadenas.
El conjunto contiene todas las soluciones del problema de búsqueda, mientras que contiene aquellas cadenas que no son soluciones. Ambos conjuntos satisfacen y , lo cual significa que y constituyen una bipartición de (todas las cadenas de bits de longitud ).
Además, se definen dos vectores unitarios que representan los estados de superposición sobre los conjuntos previamente tratados.
Donde equivale al estado de superposición de aquellas cadenas que no son soluciones, mientras que constituye la superposición de las cadenas que sí lo son. Estos vectores se encuentran definidos únicamente cuando ninguno de los conjuntos es vacío.
Además, es la probabilidad de que la medición de produzca un estado bueno. Así, es la probabilidad de que la misma medición produzca un estado malo.
Dado que contiene el estado de superposición inicial sobre todas las cadenas, se cumple la siguiente igualdad:
Por lo tanto, representa el estado del programa tras la acción de la etapa de preparación. Esto implica que justo antes de alcanzar la etapa de selección, dicho estado se encuentra contenido en un espacio vectorial abarcado por y . Siempre se tendrá esta propiedad luego de cualquier cantidad de iteraciones al encontrarse en el primer paso de la etapa de reflejo.
También considerar que la Amplificación de Amplitudes no se preocupa sobre cuáles cadenas son soluciones, solamente debe ser capaz de distinguirlas respecto de aquellas cadenas que no lo son.
El operador definido previamente puede reescribirse como , tales que y , donde aplica un reflejo en relación al vector de las no soluciones y refleja respecto del vector .
Visión matricial
Sección titulada «Visión matricial»Se aplicará sobre la base ortonormalizada tal que:
Notar que se cumple la siguiente igualdad:
Al aplicar sobre se obtiene .
Cálculo
Al aplicar sobre se obtiene .
Cálculo
Por conveniencia, se expresará la acción de en un espacio de dos dimensiones como una matriz.
donde la primera y segunda fila corresponden a y respectivamente. Dicha matriz se obtiene al multiplicar por sí misma una matriz más simple.
Cálculo
Además, la matriz
es de rotación, la cual puede expresarse como
para . Utilizando esta nueva expresión:
ya que rotar por el ángulo dos veces es equivalente a rotar por el ángulo .
Visión geométrica
Sección titulada «Visión geométrica»El estado del programa al comienzo de la primera iteración, tras la etapa de preparación es:
y el efecto de aplicar sobre dicho estado consiste en aplicar una rotación por el ángulo dentro del espacio abarcado por y .
Por ejemplo:
Regla general:
La idea es que las iteraciones roten el estado vectorial hacia . Cuando esto ocurre, una medición del estado produce con alta probabilidad una de las salidas superpuestas en , es decir, una solución al problema.
Inicialmente el estado vectorial es ortogonal respecto de . Partiendo de este punto, la operación refleja el estado en torno a , y luego la operación lo refleja en torno a . Dado que dos reflexiones producen una rotación, el vector de estado se acerca hacia , y luego de reiteradas rotaciones es posible obtener una solución con alta probabilidad mediante una observación en la base computacional.
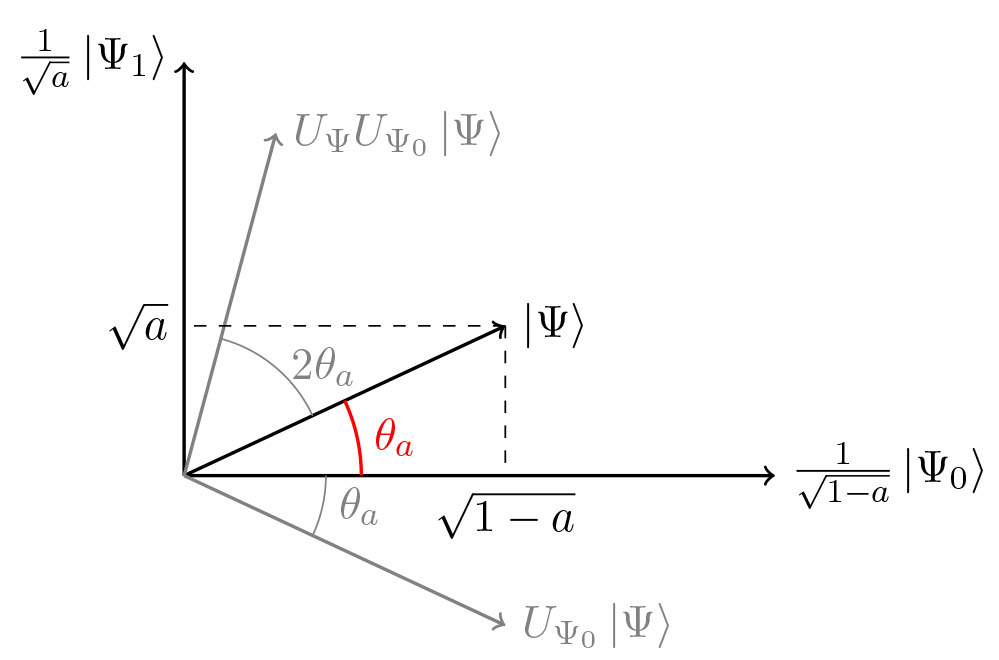
Figura (2): Rotación realizada por el operador como composición de dos reflexiones. Fuente: https://alexandre01.github.io/projects/quantum_ampl_estimation/
Complejidad
Sección titulada «Complejidad»Sea la probabilidad inicial de alcanzar una solución a partir de . Asumiendo (existe al menos una solución), y definiendo , donde se define tal que y . Entonces, si se computa (se aplica el operador veces) y se realiza una medición, la salida será buena con probabilidad de al menos , definida como el valor más grande entre y .
De esta manera, el número óptimo de iteraciones es el siguiente:
Donde es la cantidad de cubits y es la cantidad de soluciones posibles. En caso de que se desconozca, es posible recurrir a algunas técnicas para resolver el problema conservando la aceleración cuadrática.
Demostración
Dado que el estado del programa luego de iteraciones de es
debe elegirse tal que
sea tan cerca de 1 como sea posible (en valor absoluto), para maximizar la probabilidad de obtener en la medición. También es deseable que sea lo más pequeño posible, ya que aplicaciones de la operación requieren consultas a la función , cuya ejecución se busca minimizar. Una forma de lograr que sea cercano a 1 en valor absoluto consiste en elegir tal que:
Debido al comportamiento de la función seno.
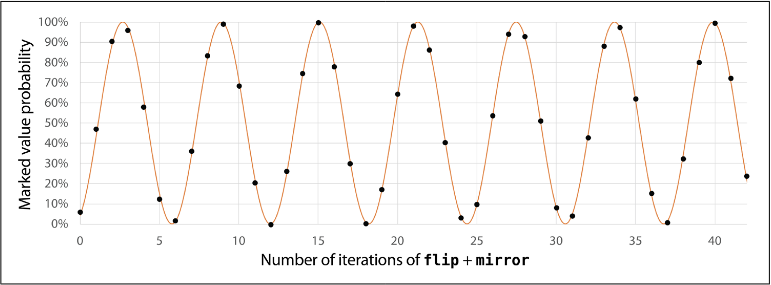
Figura (3): Comportamiento de la función seno. Probabilidad de leer una solución contra el número de iteraciones.
Despejando y redondeando a un valor entero mayor que 0, de la ecuación anterior se obtiene:
Ahora debe reemplazarse el valor . Dado que el valor de dicho ángulo está definido por la fórmula , dependiente de , la estimación de se encuentra ligada a la cantidad de soluciones y la cantidad total de elementos presentes en el espacio de búsqueda.
Solución única
Sección titulada «Solución única»Se harán los cálculos necesarios para el caso en el que solamente hay una cadena tal que . Esto quiere decir que .
Cuyo valor puede aproximarse a cuando es un valor grande.
Sustituyendo el valor en la expresión se obtiene
En base al resultado obtenido en , este caso requiere a lo sumo consultas para encontrar la solución. La probabilidad de que la medición final resulte en la solución puede expresarse como
Y en general se cumple
para todo , por lo que la probabilidad de éxito tiende a 1 a medida que crece.
Múltiples soluciones
Sección titulada «Múltiples soluciones»Se harán los cálculos necesarios para el caso en el que hayan distintas cadenas tal que .
A medida que la cantidad de elementos en varía, también lo hace el ángulo , lo cual puede repercutir en gran medida en la probabilidad de éxito del algoritmo. Teniendo soluciones, habrá que usar el siguiente ángulo:
y denota la probabilidad del algoritmo para que en iteraciones encuentre una de las soluciones dentro de posibilidades. Puede probarse que
y también que
Para todo valor se cumple que , por lo que puede afirmarse la siguiente inecuación:
lo cual implica que
Por lo tanto, se reduce la cantidad de consultas requeridas a la función a medida que aumenta. El número de consultas requeridas es de .
Número desconocido de soluciones
Sección titulada «Número desconocido de soluciones»Si el número de soluciones se desconoce debe implementarse una estrategia para encontrar soluciones con alta probabilidad. Existen diferentes alternativas que serán mencionadas a continuación.
La primera opción consiste en elegir un valor aleatorio de ubicado entre 1 y . De esta manera es posible encontrar una solución (asumiendo que al menos una existe) con una probabilidad mayor al 40%. Si bien esta probabilidad es baja, repitiendo este procedimiento y verificando el resultado puede alcanzarse una solución con una probabilidad muy cercana a 1.
Por otro lado, existe un método que encuentra una solución cuando al menos una existe realizando consultas, incluso cuando el número de soluciones de no es conocido. Cabe destacar que se requieren consultas para determinar que no hay soluciones cuando . La idea consiste en elegir de manera uniforme y aleatoria dentro del conjunto iterativamente, incrementando el valor de . Una estrategia válida es comenzar con e incrementar dicho valor exponencialmente, siempre terminando este proceso tan pronto como una solución sea encontrada y dejando de incrementar para no desperdiciar consultas cuando ya se sabe que no existe una solución. Este procedimiento tiene la ventaja de que requiere menos consultas cuando hay más soluciones. No obstante, debe tenerse cuidado a la hora de elegir la tasa de crecimiento de : está comprobado que utilizar funciona correctamente, pero duplicar en cada iteración es demasiado agresivo y genera incrementos demasiado rápidos.
Casos triviales
Sección titulada «Casos triviales»Si todas las cadenas son una solución, entonces cualquier medición reflejará una solución; y cuando no haya soluciones, ninguna medición obtendrá una solución. El hecho de que o sean vacíos implica que es una función constante: es vacío cuando para todo y es vacío cuando para todo .
Lo anterior implica que
y por lo tanto
En conclusión, sin importar la cantidad de iteraciones que se realicen en estos casos, las mediciones siempre reflejarán una cadena aleatoria .
Ejemplos
Sección titulada «Ejemplos»Sean y las soluciones a un problema que recurre a la superposición uniforme , se prepara el circuito para distinguir ambas soluciones en la fase de selección. Se sabe de antemano que el problema tiene dos soluciones.
Se analizan los pasos del algoritmo donde:
- es el estado inicial
- se corresponde con la preparación del estado cuántico que resulta en
- representa el resultado de aplicar la operación de selección
- es el efecto de la etapa de reflejo
En y se utilizará como subíndice el número de iteración.
La cantidad óptima de iteraciones es:
El estado inicial del algoritmo
Estado cuántico luego de la preparación (aplicación del algoritmo )
Notar que y tienen invertida la fase
Notar la “deselección” de y
Notar que no “deselecciona” ya que alcanzó la cantidad óptima de iteraciones.
Llegados a este punto, el problema se encuentra resuelto con una probabilidad de 96.875%, ya que las probabilidades individuales de obtener o son de 47.2656%, y sumadas dan la probabilidad total de llegar a una solución. Se realiza una tercera iteración para mostrar el decremento de la probabilidad al exceder la cantidad óptima de iteraciones.
Por lo que en una tercera iteración se disminuyen las probabilidades de encontrar una de las soluciones.
from qiskit import QuantumCircuit, circuit, transpilefrom qiskit_aer import QasmSimulator
QUBIT_COUNT = 4QUBITS = range(QUBIT_COUNT)ITERATIONS = 2NUMBERS_TO_FIND = [1, 3]A = circuit.library.HGate()
def run_circuit(qc: QuantumCircuit): sim = QasmSimulator() transpiled_qc = transpile(qc) result = sim.run(transpiled_qc).result() return result
def flip(qc: QuantumCircuit, nums_to_find: list[int]): """ Aplica la operación de selección sobre los números recibidos en 'nums_to_find'. Para cada número en 'nums_to_find', esta función voltea su fase. Un número N se representa como un estado computacional |N⟩. """ for num in nums_to_find: # Determine the qubits that need an X gate to transform |num⟩ to |1...1⟩. # These are the qubits that are '0' in the binary representation of num. # Qiskit's convention: q0 is LSB. # Example: num=1 (0001 for 4 qubits), X applied to q1, q2, q3. # Example: num=3 (0011 for 4 qubits), X applied to q2, q3.
qubits_to_apply_x = [] for i in range(QUBIT_COUNT): # Check if the i-th bit of num (from LSB) is 0 if not (num & (1 << i)): qubits_to_apply_x.append(i)
# Apply X gates to transform |num⟩ to |1...1⟩ if qubits_to_apply_x: qc.x(qubits_to_apply_x)
# Apply multi-controlled Z gate (MCZ) to flip the phase of |1...1⟩. # ZGate().control(N-1) applied to N qubits acts as an MCZ gate # that flips the phase of the state |1⟩^{otimes N}. if QUBIT_COUNT > 0: mcz_gate = circuit.library.ZGate().control(QUBIT_COUNT - 1) qc.append(mcz_gate, QUBITS)
# Apply X gates again to transform back from |1...1⟩ to |num⟩ if qubits_to_apply_x: qc.x(qubits_to_apply_x)
return qc
def mirror(qc: QuantumCircuit): """ Aplica el operador espejo al circuito cuántico También llamado operador de difusión de Grover Utilizando el algoritmo de superposición A """ for qubit_idx in QUBITS: qc.append(A, [qubit_idx])
qc.x(QUBITS)
if QUBIT_COUNT > 0: mcz_gate = circuit.library.ZGate().control(QUBIT_COUNT - 1) qc.append(mcz_gate, QUBITS)
qc.x(QUBITS)
for qubit_idx in QUBITS: qc.append(A, [qubit_idx])
return qc
def analyze_aa_results(results): counts = results.get_counts() print("Resultados (counts):", counts)
# Calculate total shots for percentages total_shots = sum(counts.values()) if total_shots == 0: print("Porcentajes: No shots found.") return
# Calculate percentages # Qiskit measurement string is MSB first, e.g., '0001' for 4 qubits. # This corresponds to decimal 1. percentages = {} for bitstring, count in counts.items(): decimal_value = int(bitstring, 2) percentages[decimal_value] = (count / total_shots) * 100
ordered_percentages = dict(sorted(percentages.items(), key=lambda item: item[1], reverse=True))
print("Porcentajes (ordenados):") for val, perc in ordered_percentages.items(): binary_representation = format(val, f'0{QUBIT_COUNT}b') print(f" Estado |{binary_representation}⟩ (Decimal {val}): {perc:.2f}%")
# Create Quantum Circuitqc = QuantumCircuit(QUBIT_COUNT, QUBIT_COUNT)
# 1. Initialize state to uniform superposition: H^{otimes n} |0...0⟩for qubit_idx in QUBITS: qc.append(A, [qubit_idx])
# 2. Iterationsfor iteration in range(ITERATIONS): qc.barrier() # Apply phase flip for solutions qc = flip(qc, NUMBERS_TO_FIND) qc.barrier() # Apply Diffusion operator (mirror) qc = mirror(qc) qc.barrier()
# 3. Measurementqc.measure(QUBITS, QUBITS)
# Print the circuitprint("Diagrama del circuito cuántico:")print(qc.draw(output='text'))
# Run the circuit and analyze resultsprint("Ejecutando el circuito...")results = run_circuit(qc)analyze_aa_results(results)Diagrama del circuito cuántico: ┌───┐ ░ ░ ┌───┐┌───┐ ┌───┐┌───┐ ░ ░ ░ ┌───┐┌───┐ ┌───┐┌───┐ ░ ┌─┐q_0: ┤ H ├─░───────■────────────■───────░─┤ H ├┤ X ├─■─┤ X ├┤ H ├─░──░───────■────────────■───────░─┤ H ├┤ X ├─■─┤ X ├┤ H ├─░─┤M├───────── ├───┤ ░ ┌───┐ │ ┌───┐ │ ░ ├───┤├───┤ │ ├───┤├───┤ ░ ░ ┌───┐ │ ┌───┐ │ ░ ├───┤├───┤ │ ├───┤├───┤ ░ └╥┘┌─┐q_1: ┤ H ├─░─┤ X ├─■─┤ X ├──────■───────░─┤ H ├┤ X ├─■─┤ X ├┤ H ├─░──░─┤ X ├─■─┤ X ├──────■───────░─┤ H ├┤ X ├─■─┤ X ├┤ H ├─░──╫─┤M├────── ├───┤ ░ ├───┤ │ ├───┤┌───┐ │ ┌───┐ ░ ├───┤├───┤ │ ├───┤├───┤ ░ ░ ├───┤ │ ├───┤┌───┐ │ ┌───┐ ░ ├───┤├───┤ │ ├───┤├───┤ ░ ║ └╥┘┌─┐q_2: ┤ H ├─░─┤ X ├─■─┤ X ├┤ X ├─■─┤ X ├─░─┤ H ├┤ X ├─■─┤ X ├┤ H ├─░──░─┤ X ├─■─┤ X ├┤ X ├─■─┤ X ├─░─┤ H ├┤ X ├─■─┤ X ├┤ H ├─░──╫──╫─┤M├─── ├───┤ ░ ├───┤ │ ├───┤├───┤ │ ├───┤ ░ ├───┤├───┤ │ ├───┤├───┤ ░ ░ ├───┤ │ ├───┤├───┤ │ ├───┤ ░ ├───┤├───┤ │ ├───┤├───┤ ░ ║ ║ └╥┘┌─┐q_3: ┤ H ├─░─┤ X ├─■─┤ X ├┤ X ├─■─┤ X ├─░─┤ H ├┤ X ├─■─┤ X ├┤ H ├─░──░─┤ X ├─■─┤ X ├┤ X ├─■─┤ X ├─░─┤ H ├┤ X ├─■─┤ X ├┤ H ├─░──╫──╫──╫─┤M├ └───┘ ░ └───┘ └───┘└───┘ └───┘ ░ └───┘└───┘ └───┘└───┘ ░ ░ └───┘ └───┘└───┘ └───┘ ░ └───┘└───┘ └───┘└───┘ ░ ║ ║ ║ └╥┘c: 4/══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╩══╩══╩══╩═ 0 1 2 3
Ejecutando el circuito...Resultados (counts): {'1110': 1, '0000': 2, '0001': 492, '1111': 5, '0011': 483, '0111': 1, '1011': 2, '1100': 4, '0010': 5, '0100': 3, '1001': 4, '0101': 6, '1000': 6, '0110': 3, '1101': 3, '1010': 4}Porcentajes (ordenados): Estado |0001⟩ (Decimal 1): 48.05% Estado |0011⟩ (Decimal 3): 47.17% Estado |0101⟩ (Decimal 5): 0.59% Estado |1000⟩ (Decimal 8): 0.59% Estado |1111⟩ (Decimal 15): 0.49% Estado |0010⟩ (Decimal 2): 0.49% Estado |1100⟩ (Decimal 12): 0.39% Estado |1001⟩ (Decimal 9): 0.39% Estado |1010⟩ (Decimal 10): 0.39% Estado |0100⟩ (Decimal 4): 0.29% Estado |0110⟩ (Decimal 6): 0.29% Estado |1101⟩ (Decimal 13): 0.29% Estado |0000⟩ (Decimal 0): 0.20% Estado |1011⟩ (Decimal 11): 0.20% Estado |1110⟩ (Decimal 14): 0.10% Estado |0111⟩ (Decimal 7): 0.10%